So, I've been quiet on this blog for a little over a year. Yikes! The root cause of this radio silence has been that I've been experimenting with a lot of technology and software, working to restructure our CollectiveAccess instance, and creating new workflows. One of those new workflows arose from the question: how can we make site survey form entry into SCHPR more efficient?
Do you know what a site survey form looks like? No? See the one below for an example. This site survey form is from Box 15 of Series 108042.
Do you know what a site survey form looks like? No? See the one below for an example. This site survey form is from Box 15 of Series 108042.

Heretofore, both myself and my summer interns were doing data entry by hand. By that, I mean we would create a new entry in SCHPR and, while referencing the site survey form, fill in fields for "Site No.," "County," "Historic Name," etc. It took quite a while as you can imagine, and it didn't seem like a good and efficient use of anyone's time. So, at the suggestion of some colleagues at University of South Carolina, we began to explore more efficient methods either fully or semi automated with the use of a coded program or at least with the use of an OCR editor.
We decided to try using adobe to OCR the scans, and export them in the format of an excel spreadsheet. Both I and a colleague experimented with this method to see if it yielded acceptable results. Unfortunately, it did not for two primary reasons: the number of extreme errors in the OCR text results and the incorrect orientation of data in excel that adobe defaulted to when exporting text. See a snapshot below for an example.
We decided to try using adobe to OCR the scans, and export them in the format of an excel spreadsheet. Both I and a colleague experimented with this method to see if it yielded acceptable results. Unfortunately, it did not for two primary reasons: the number of extreme errors in the OCR text results and the incorrect orientation of data in excel that adobe defaulted to when exporting text. See a snapshot below for an example.
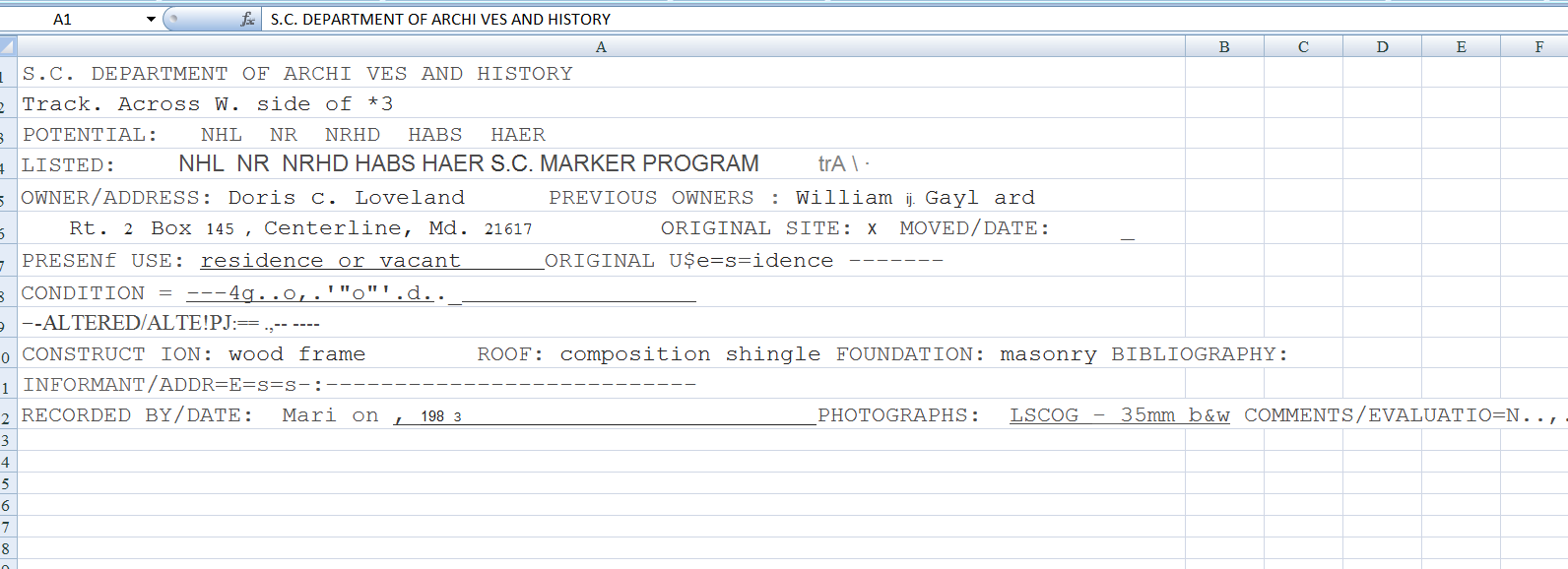
In addition to poor OCR accuracy of the document, Adobe failed to catch and represent all typed data. Lacking a user interface that would allow an archivist to delineate which fields corresponded to filled in data, there was no way to create a structured, template excel spreadsheet from each card. Another problem with this method is the sometimes irregular occurrence of continued fields on the back of SHPO site cards. Unfortunately, on these continuation sheets, fields are not always marked identically. For example, a continued description field may have any of the following headings if not something altogether different: “*”, “1.”, “Description Cot’d”, etc. This lack of standardization on the source material only serves to make using Adobe, with its lack of a User Interface to differentiate between fields, more problematic.
By November, we were exploring other options. While at a professional conference in North Carolina, I questioned other digital archivists about better OCR technology that could help us to extract text from our site forms and use in a database. It was at this time that ABBYY FineReader was suggested. Upon returning to South Carolina, I researched ABBYY FineReader projects, and I found a recent presentation by a group from University of Maryland at MARAC (Mid-Atlantic Regional Archives Conference) 2016. This group presented on using ABBYY FineReader in conjunction with a Python script to extract data from urban renewal documents. View the presentation here. Relevant pages are 19-24.
In December 2016, I got in touch with the project group members (Greg Jansen, Mary Kendig, and Myeong Lee) to ask for further information and guidance. At this time, I also got in touch with a colleague at UNC-Chapel Hill. The digitization lab there has ABBYY FineReader and ran ten sample cards through the system in order to help us gauge the accuracy and efficiency of ABBYY for our documents.
In January 2017, we were able to access the University of Maryland’s virtual environment (courtesy of Mary Kendig) in order to use ABBYY FineReader. This trial period allowed us to ascertain ease of use, different aspects of the user interface, and software efficiency. At the end of February/beginning of March, we obtained a 30 day free trial of ABBYY FineReader 14 from the vendor. We used this to begin experimenting on a box of site survey cards.
By November, we were exploring other options. While at a professional conference in North Carolina, I questioned other digital archivists about better OCR technology that could help us to extract text from our site forms and use in a database. It was at this time that ABBYY FineReader was suggested. Upon returning to South Carolina, I researched ABBYY FineReader projects, and I found a recent presentation by a group from University of Maryland at MARAC (Mid-Atlantic Regional Archives Conference) 2016. This group presented on using ABBYY FineReader in conjunction with a Python script to extract data from urban renewal documents. View the presentation here. Relevant pages are 19-24.
In December 2016, I got in touch with the project group members (Greg Jansen, Mary Kendig, and Myeong Lee) to ask for further information and guidance. At this time, I also got in touch with a colleague at UNC-Chapel Hill. The digitization lab there has ABBYY FineReader and ran ten sample cards through the system in order to help us gauge the accuracy and efficiency of ABBYY for our documents.
In January 2017, we were able to access the University of Maryland’s virtual environment (courtesy of Mary Kendig) in order to use ABBYY FineReader. This trial period allowed us to ascertain ease of use, different aspects of the user interface, and software efficiency. At the end of February/beginning of March, we obtained a 30 day free trial of ABBYY FineReader 14 from the vendor. We used this to begin experimenting on a box of site survey cards.
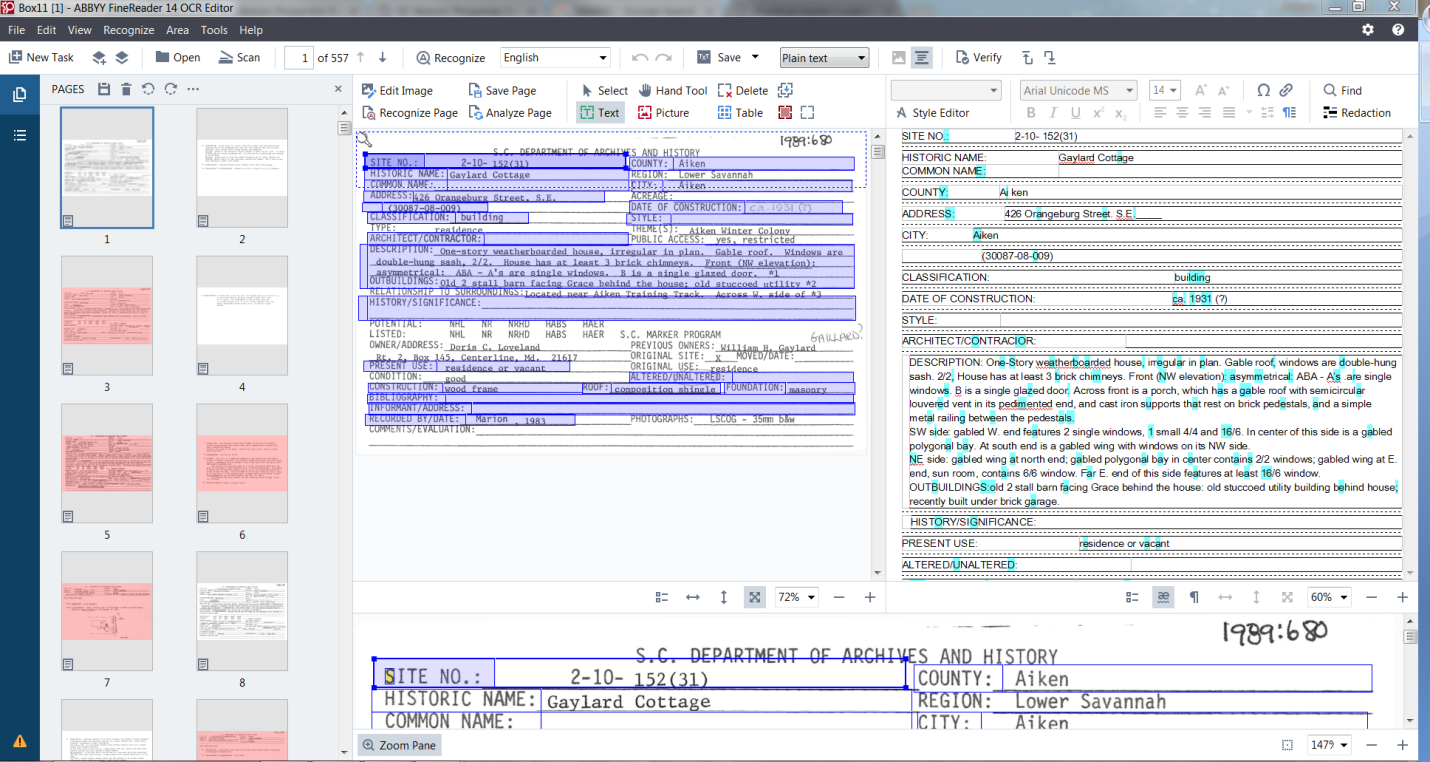
ABBYY FineReader 14 has several parts. The primary aspect that we are taking advantage of is the OCR Editor. The user interface has four viewing panes: the thumbnails on the left, the card layout in the top middle, the recognized text in the top right, and the zoomed view of the card on the bottom. Part of what is so advantageous about ABBYY aside from the accuracy of the OCR technology is the ability to be selective about what we recognize from the card and organize it accordingly. To utilize this feature to our fullest ability, we created tables to recognize labels and their associated data. We then saved this table layout as a template that can then be applied to all similar cards and tweaked as necessary. We determined that this method was more efficient than a general text capture of the document by an average of 45 seconds per card.
On Friday, March 17, 2017, we purchased ABBYY FineReader 14 Corporate. The software is a one time purchase without an annual fee.
Overall, we've been able to utilize our interns to the fullest by having them focus on a process that we cannot automate (scanning) as we work on automating the data entry process. We did not ultimately pursue the idea of using a Python script. We did experiment with this process, but it proved cumbersome with our site survey forms for several reasons: the lack of standard language, the lack of standard continuation denotation on the versos of site survey forms, etc. However, we are able to use ABBYY to create large excel spreadsheets equivalent to a box of data at a time, and then upload this metadata to SCHPR in batch.
I would definitely recommend ABBYY FineReader to other archivists, and I'm glad someone recommended it to me.
On Friday, March 17, 2017, we purchased ABBYY FineReader 14 Corporate. The software is a one time purchase without an annual fee.
Overall, we've been able to utilize our interns to the fullest by having them focus on a process that we cannot automate (scanning) as we work on automating the data entry process. We did not ultimately pursue the idea of using a Python script. We did experiment with this process, but it proved cumbersome with our site survey forms for several reasons: the lack of standard language, the lack of standard continuation denotation on the versos of site survey forms, etc. However, we are able to use ABBYY to create large excel spreadsheets equivalent to a box of data at a time, and then upload this metadata to SCHPR in batch.
I would definitely recommend ABBYY FineReader to other archivists, and I'm glad someone recommended it to me.






 RSS Feed
RSS Feed
